Word Error Rate reveals the accuracy of the speech recognition system
Word Error Rate (WER) is a commonly used measure to evaluate the accuracy of speech recognition systems. WER measures how many errors a speech recognition system makes when converting speech to text. WER is calculated by comparing the recognized text to the original manuscript and identifying differences such as added, missing or misrecognized words.
WER is calculated as follows:
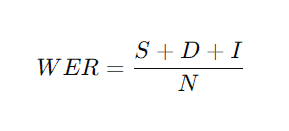
- S is incorrectly replaced words (Substitutions),
- D is missing words (Deletions),
- I is inserted words (Insertions),
- N is the number of words in the original text.
In practice, WER can be used to evaluate the performance of the speech recognition system in different usage situations. It is a key metric when developing and improving automatic speech recognition systems, which are also used as an aid in, for example, Spoken’s subtitling and transcription services.
The lower the WER, the more accurate the speech recognition system. Reducing WER is, therefore, a primary objective for companies and researchers focused on advancing speech recognition technology.
Whisper and WER values for different languages
At Spoken, we use OpenAI’s Whisper speech recognition model for speech recognition, for which the WER values vary depending on the language. In English speech recognition, the WER is usually the lowest and thus the best, due to the large amount of data available and the fact that the model has been optimized for the English language.
For English, the WER can be as low as 5–6%. In Swedish, Norwegian and Danish speech recognition, the WER values are slightly higher than this, around 8–10%. In Finnish, the WER can be even higher than this, around 10–12%, due to the unique structure and morphology of the Finnish language, which poses special challenges for speech recognition systems.
This comparison shows that while Whisper is very efficient for many languages, language structure and data availability have a significant impact on WER.